GPT-4.1 is released and we put it to the test.

Today, I’m excited to introduce OpenAI’s latest models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. These models represent significant advancements over their predecessors, GPT-4o and GPT-4o mini, especially in coding capabilities and instruction adherence. One of the most impressive upgrades is the dramatically expanded context window—now supporting up to 1 million tokens, an 8x increase from the previous 128k limit. This means the models can process and understand ultra-long documents more effectively than ever before. In terms of long-context reasoning and comprehension, these models show remarkable progress. Additionally, with their knowledge base updated to June 2024, they offer more reliable support for complex tasks by staying current with the latest information.
Key Highlights
For me, the biggest highlight of GPT-4.1 is its improved ability to follow instructions and handle long-context conversations. As an AI enthusiast, I know how crucial it is for a model to strictly follow user instructions in complex tasks. In the past, we often had to rely on “prompt engineering” tricks—like, “Please make sure not to do this, or my boss will be furious”—to get the desired results. Now, with GPT-4.1, these tricks are no longer necessary, as the model accurately understands and executes every user request.
Real-World Testing Experience
To thoroughly evaluate its capabilities, I tested the GPT-4.1 model on the Monica platform. I designed two tasks focusing on memory and style consistency, as well as code generation and creative output.
Task 1: Memory & Style Consistency
This task examined how well GPT-4.1 remembers context over multiple turns and maintains distinct writing styles. First, I asked it to write a story in the style of Mark Twain, then rewrite the story in Hemingway’s style, and finally switch back to Mark Twain for a new story. Afterward, I asked it to recall the content of the original Mark Twain story.
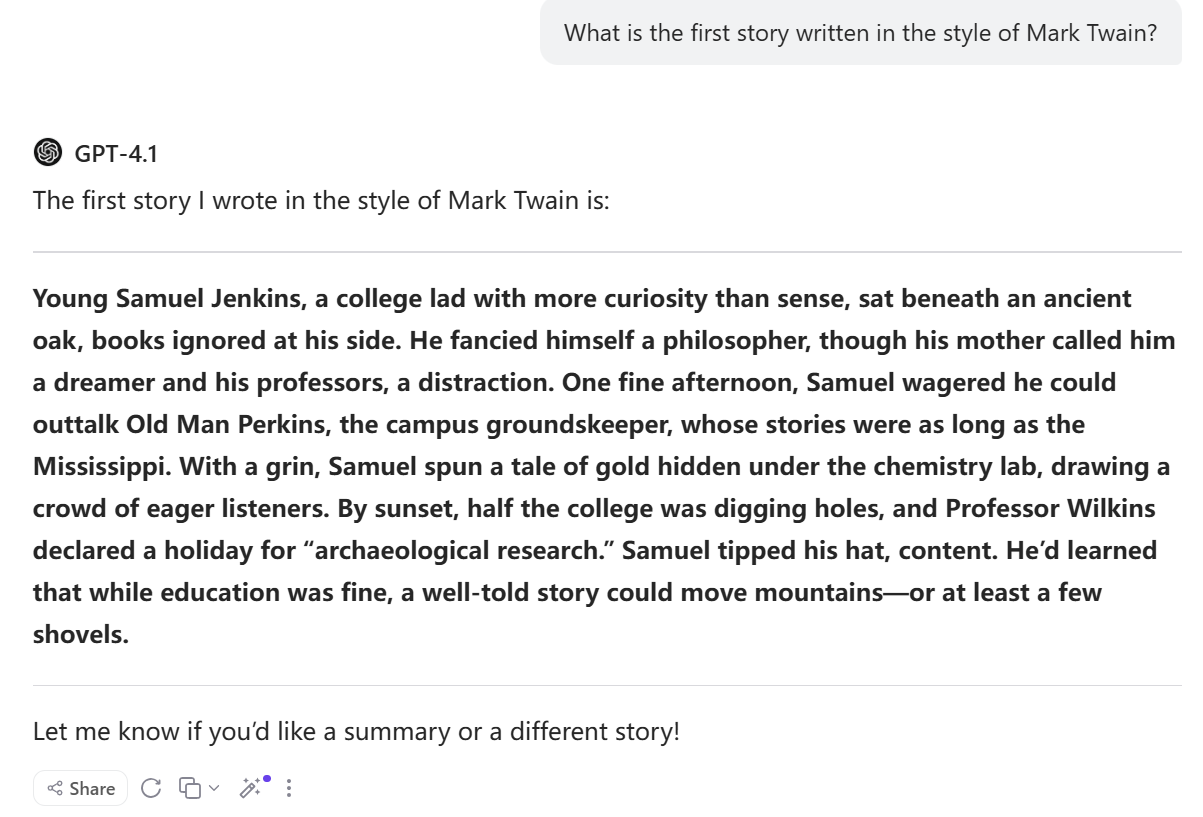
The results were impressive. GPT-4.1 not only distinguished clearly between Mark Twain and Hemingway in terms of word choice, sentence structure, and narrative rhythm, but also maintained consistency when switching back to Mark Twain’s style. Most notably, it accurately recalled the main points—and even the details—of the original story when prompted. This level of memory and contextual understanding is rare among previous models, which often “forgot” earlier content or mixed up styles. With GPT-4.1, the performance is nearly on par with human conversation and writing.
Task 2: Code & Creative Generation
For the second test, I focused on GPT-4.1’s practical application in real projects, especially its creativity and initiative. I asked it to design a website dedicated to Titian’s masterpiece Assumption of the Virgin, including related works by other artists, and to uncover connections between these artworks. I deliberately did not provide a direct image link for Assumption of the Virgin, nor did I give any specific instructions for the website design—I simply gave it a few image links to related artworks.
Once again, GPT-4.1 exceeded my expectations. It intuitively recognized Assumption of the Virgin as the central theme and made it the focal point of the website(even though it wasn’t able to display the image correctly). Even more impressive, it chose a red-and-gold Renaissance-inspired color scheme, echoing Titian’s artistic preferences and the sacred atmosphere of altarpieces. When I inquired further, it explained that the palette was inspired by Venetian Renaissance art, with red symbolizing passion and gold representing divinity.
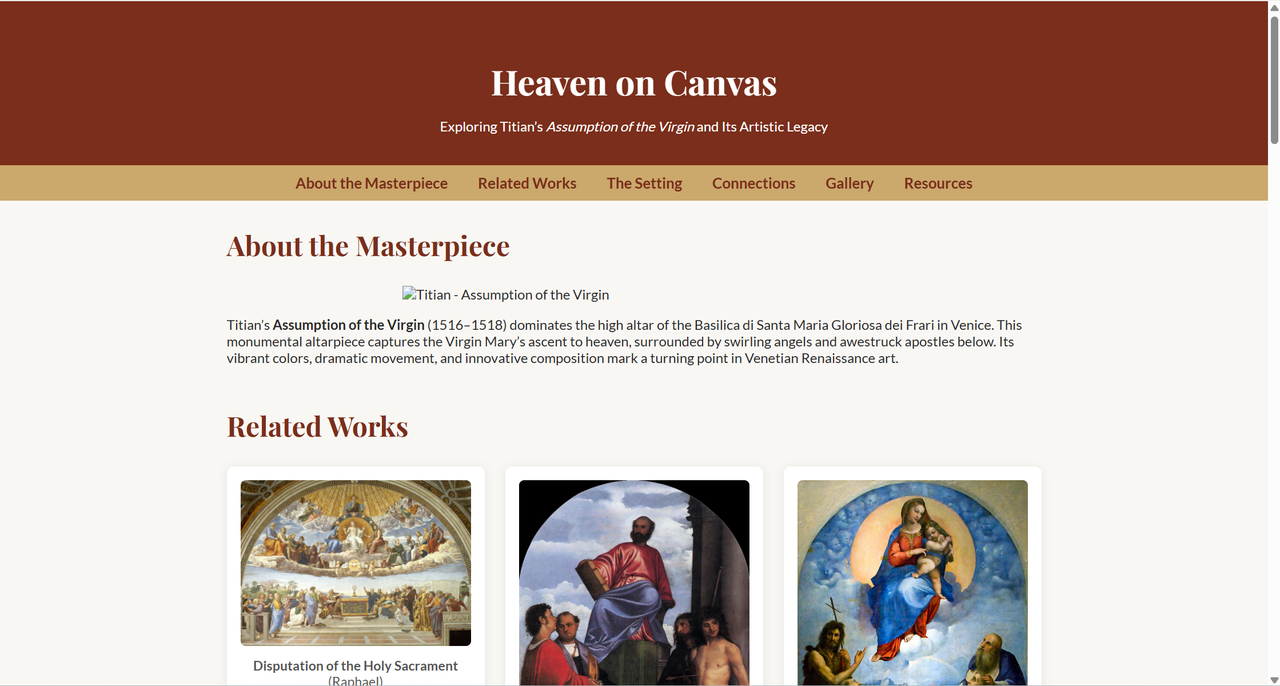
Moreover, GPT-4.1 demonstrated strong copyright awareness, automatically attributing all images at the bottom of the site—a critical feature for compliance.
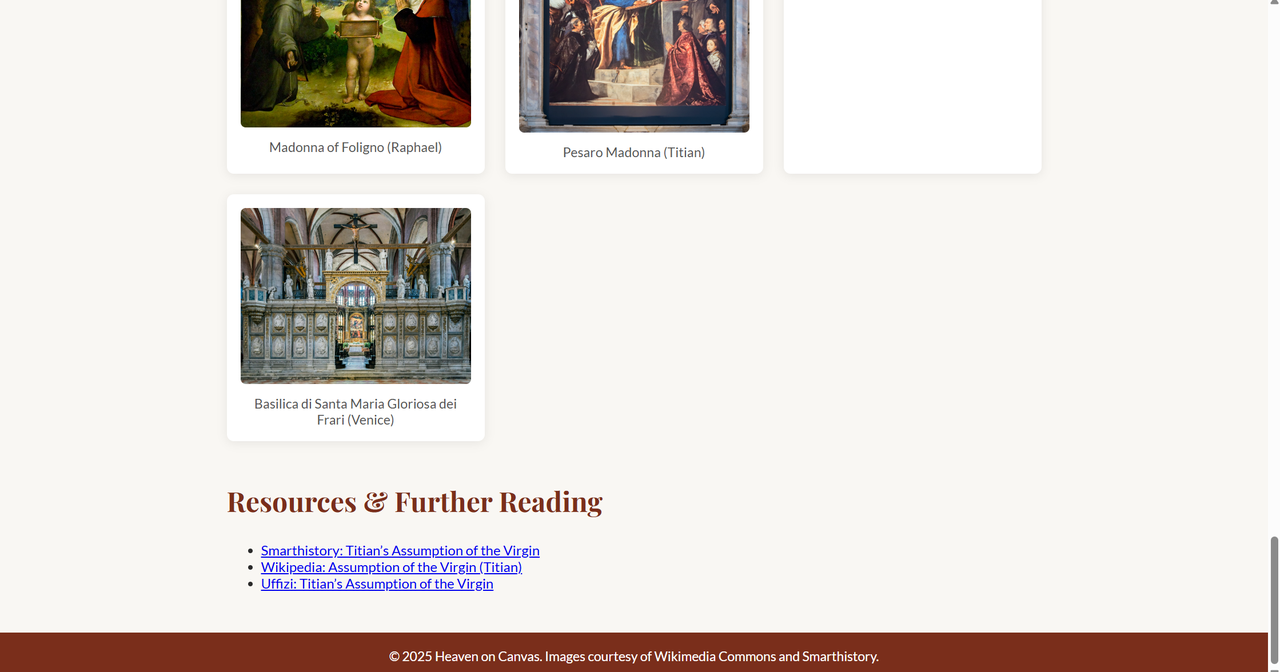
It also correctly identified related works, such as Pesaro Madonna, and placed them in context.
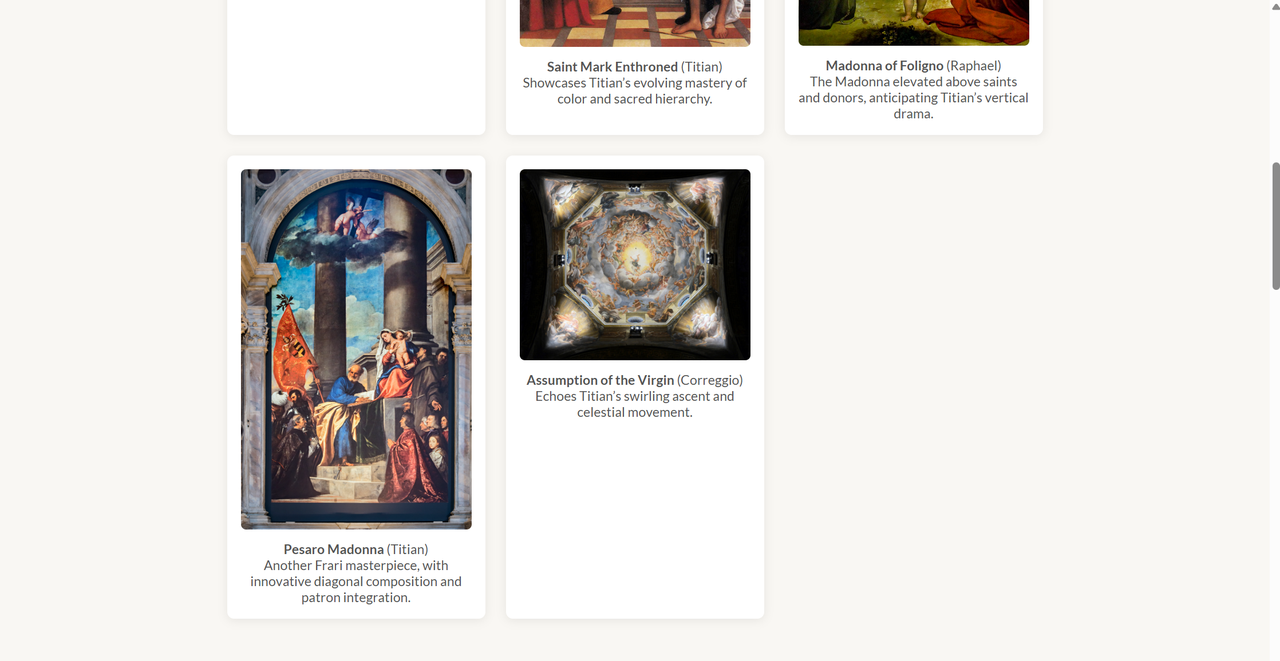
In addition, it also noticed that one of the images was not an artwork by the artist, but rather the location where “Assumption of the Virgin” is displayed. It assigned an appropriate place for this photo within the website’s structure, instead of removing it.

Of course, GPT-4.1 isn’t perfect. Some of its deeper art historical connections were a bit speculative, such as its interpretation of Raphael’s Madonna of Foligno. However, considering the limited information I provided, its performance was still highly satisfactory. Overall, GPT-4.1 shows unprecedented capabilities in understanding requirements, generating creative content, managing styles, and handling details.
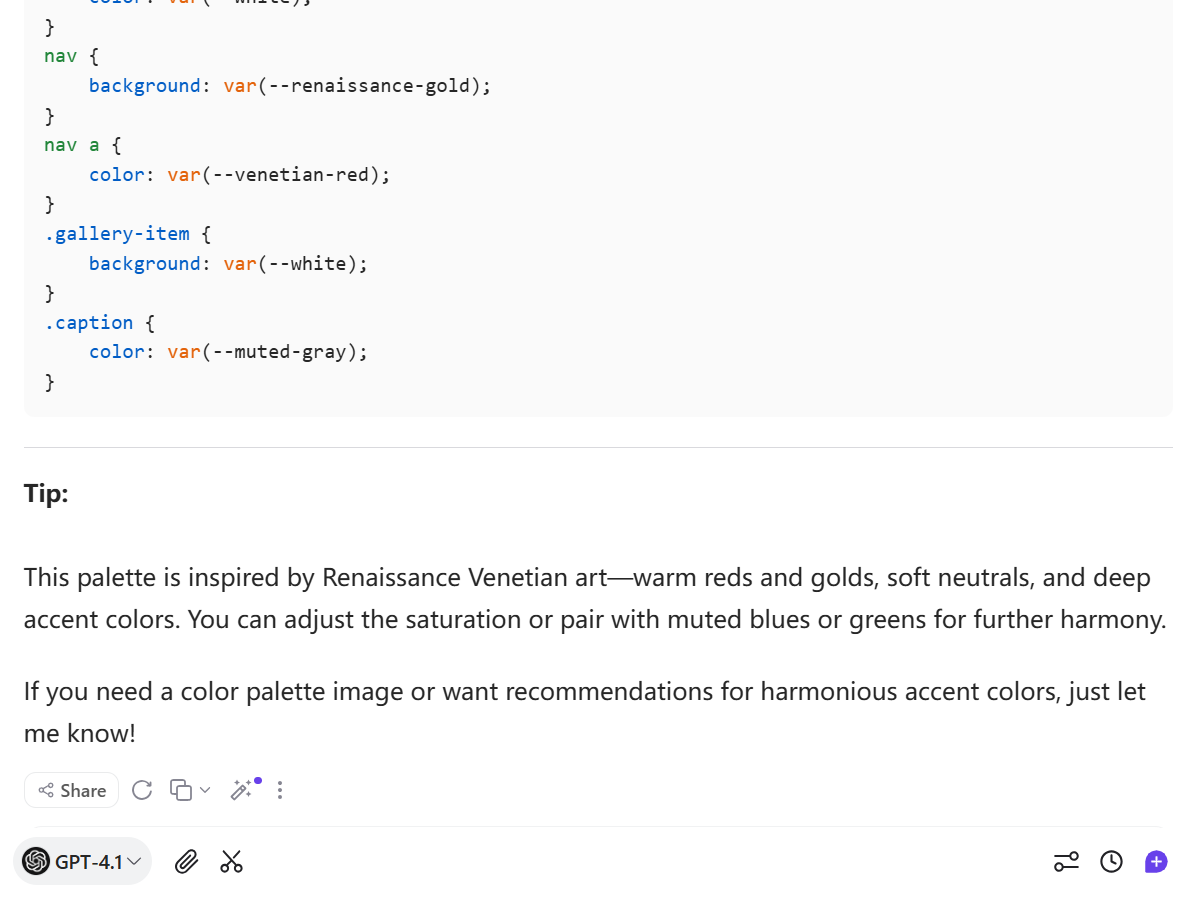
During my actual interaction with GPT-4.1, there was another detail that left a deep impression on me—its performance in website color scheme design. As an art enthusiast, I am highly sensitive to color. What surprised me was that GPT-4.1 chose a deep red and gold Renaissance-inspired palette for the Titian-themed website. This was not only an aesthetic match, but also demonstrated its profound understanding of art history and the context of the works.
When I further asked about the inspiration behind the color scheme, GPT-4.1 told me that the palette was inspired by the artistic style of the Venetian Renaissance. Red represents the passion and power found in Titian’s paintings, while gold symbolizes the sacredness and solemnity of altarpieces. It not only provided specific color parameters, but also carefully distinguished the color combinations for different parts of the website, such as the main background, navigation bar, text, and cards.
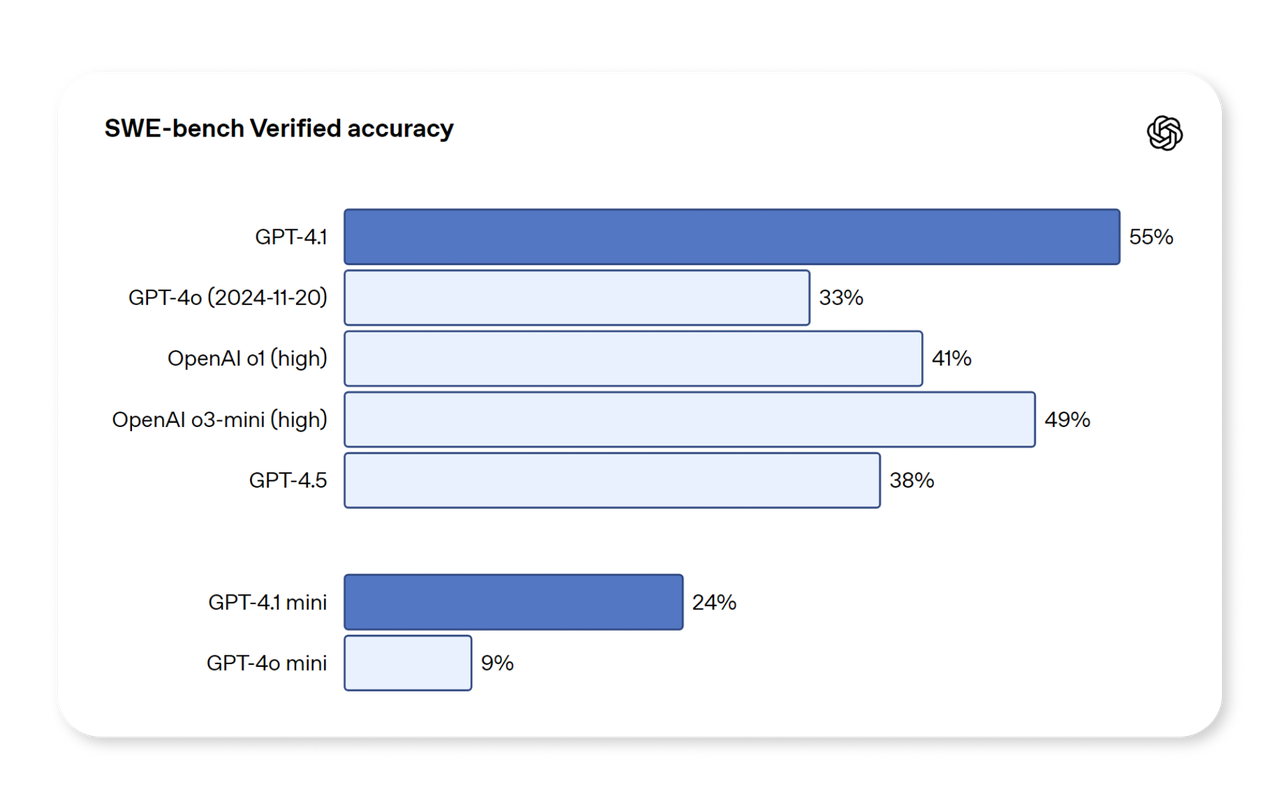
Benchmark Data
While my hands-on experience gave me confidence in GPT-4.1, I also looked at its performance in industry-standard benchmarks. The data is equally compelling:
- In the SWE-bench Verified benchmark, GPT-4.1 scored 54.6%, a 21.4% improvement over GPT-4o and 26.6% higher than GPT-4.5. This makes it a leader in code understanding, repair, and generation—crucial for developers seeking powerful AI tools.
- For instruction following, GPT-4.1 scored 38.3% on the Scale MultiChallenge benchmark, up 10.5% from the previous generation. This directly translates to smoother, more efficient user interactions.
- In the Video-MME benchmark (long, no subtitles category), GPT-4.1 achieved a 72.0% score, 6.7% higher than GPT-4o, demonstrating its strength in multimodal tasks.

It’s worth noting that GPT-4.1 mini also shines, outperforming GPT-4o in many benchmarks while being faster and more cost-effective. GPT-4.1 nano is ideal for tasks like classification and autocomplete, thanks to its speed and low cost.
Official Demo Highlights
During the official gpt 4.1 release presentation, several demo cases caught my attention. The most impressive was website generation: with just a simple prompt, GPT-4.1 handled the entire process, producing a well-structured, content-rich site. Its flexibility and accuracy in handling subsequent complex tasks were remarkable.
For example, one demo involved uploading a log file containing 45,000 tokens and asking GPT-4.1 to find the only line that wasn’t in HTML format. The model handled this massive data set with ease and speed—an ability with huge implications for industries like finance, law, and customer service.
Another demo tested strict compliance with formatting instructions, where the model was required to output content only under specific conditions. Previous models often struggled with such “negative” tasks, but GPT-4.1 performed flawlessly.
GPT 4.1 Free Access and GPT 4.1 Price
Many users are curious about GPT 4.1 free access. Currently, Monica offers unlimited access to GPT-4.1 for its subscription users. While some platforms may provide limited free trials or restricted usage, Monica subscribers can enjoy full, unrestricted use of GPT-4.1, making it an excellent choice for those who require consistent and high-volume access. The gpt 4.1 price on Monica is highly competitive and offers great value, especially with the availability of the mini and nano versions for even more cost-effective solutions.
Try GPT 4.1 on Monica
Conclusion
In summary, the gpt 4.1 release marks a major milestone in practical AI applications. By closely aligning with real-world developer needs, these models open up new possibilities for building intelligent systems and complex agent applications. I’m inspired by the creativity of the developer community and look forward to seeing the amazing projects built with GPT-4.1.